Creating safe AGI that benefits all of humanity
2022 年末,OpenAI 推出的 ChatGPT 横空出世,其惊人的推理,对话能力仿佛让人看到真正的人工智能就要诞生。那么其背后的奥义原理是什么,大语言模型(Large Language Model)对我们有什么影响,我们又如何掌握并利用大语言模型的能力呢?在这篇文章中,笔者以一个 AI 零基础的程序员角度出发,简单阐述大语言模型的由来和原理。
语言学以及 NLP
在探究 LLM 之前,笔者想要先讨论下其诞生的背景以及相关的领域知识。正如 LLM 的名称所示,大语言模型也是一种语言模型,而语言模型即 NLP 领域的终极目的是什么呢,这里引用维基百科的定义:
Natural language processing (NLP) is an interdisciplinary subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of “understanding” the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.
其中最为重要的就是「understanding」,对于如何理解人类语言内容主要有两条道路或者说方法,即「基于统计的经验主义与基于规则的理性主义」:
- 理性主义(符号主义):NLP 领域企图完全解构人类的语言文字的所有细节,以期建立起一套理论,就像数学一样,能够精准描述我们在语言文字中显式、隐式包含的信息,更多的从语言学的角度去进行分析处理。。
- 经验主义(连接主义):给机器灌输一些文本信息后,机器能够自己抽取其中的特征信息,学会语言文字背后的「知识」,更多从统计学的角度去体现。
而最近五年中随着算力(GPU)的提升,以及各种 NLP 模型的诞生与演进,基于经验主义的 NLP 大放异彩,由此诞生了 LLM 这个令人惊诧的东西。神经网络,深度学习等各方面工程化的发展,让算法工程师更多的从效果角度出发优化,暂时没有统一的指导思想,也因此诞生了我们似乎暂时无法完全理解的成果。那么在我们了解了 NLP 的最基础背景后,我们回到 NLP 领域一个最朴素也是最重要的问题:给你一组文本内容,预测下一个出现的词可能是什么?
统计语言模型:N-gram Language Model
将文本中的词按照一定的顺序进行组合,形成一个序列,下一个词出现的概率只依赖于它前面 n-1 个词,然后用这个序列来预测下一个词,这也叫做 N 元文法。N-gram模型是基于统计的,它通过计算训练语料库中的n-gram出现的频率来预测下一个词。比如,假设我们有以下句子:
- “The cat sat on the mat”
- “The cat ate the mouse”
- “The mouse sat on the mat”
对于2-gram模型(bigram),我们可以计算以下的条件概率:
- P(“sat” | “The cat”) = 1 / 2
- P(“ate” | “The cat”) = 1 / 2
- P(“on” | “cat sat”) = 1
- P(“the” | “sat on”) = 1
所以输入为 “The cat”,预测下一个单词是 “sat” 或者 “ate”,他们的概率都是 1/2。非常明显我们可以看出这种语言模型的缺陷:
- N 比较大时,训练数据中找不到足够的 n-gram 实例。
- 只能依赖前 N-1 个词。
- 每个词之间其实是有一定关联的,n-gram 模型没有体现出来。
神经网络
神经网络作为一种机器学习方法,在很多方面解决了基于统计学的语言模型问题,这里简单介绍下神经网络的原理:
神经元
神经网络的基本计算单元,也被称作节点(node)或者单元(unit)。它可以接受来自其他神经元的输入或者是外部的数据,然后计算一个输出。每个输入值都有一个权重(weight),权重的大小取决于这个输入相比于其他输入值的重要性。然后在神经元上执行一个特定的函数 f, 定义如下图所示,这个函数会该神经元的所有输入值以及其权重进行一个操作。
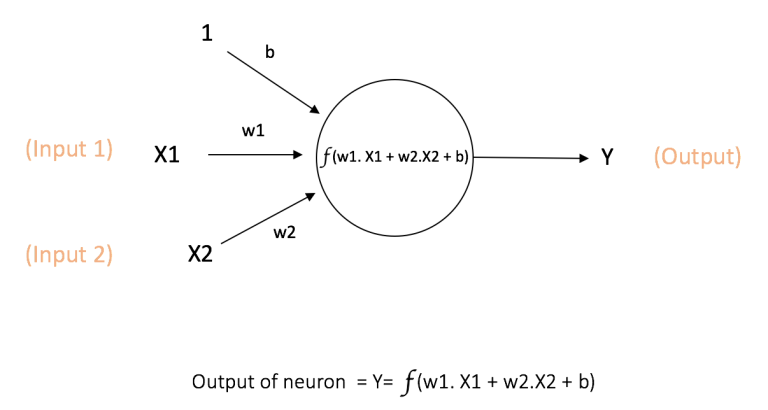
f 是非线形函数给神经网络引入非线形,例如 Sigmoid: 输出范围是[0,1],b 是偏置值bias: 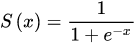
前向神经网络
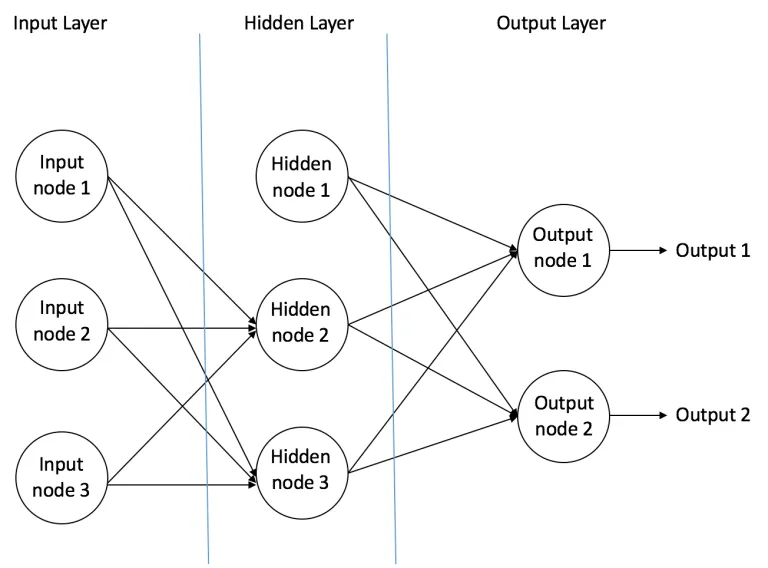
- 输入神经元:位于输入层,主要是传递来自外界的信息进入神经网络中,比如图片信息,文本信息等,这些神经元不需要执行任何计算,只是作为传递信息,或者说是数据进入隐藏层。
- 隐藏神经元:位于隐藏层,隐藏层的神经元不与外界有直接的连接,它都是通过前面的输入层和后面的输出层与外界有间接的联系,因此称之为隐藏层,上图只是有1个网络层,但实际上隐藏层的数量是可以有很多的,远多于1个,当然也可以没有,那就是只有输入层和输出层的情况了。隐藏层的神经元会执行计算,将输入层的输入信息通过计算进行转换,然后输出到输出层。
- 输出神经元:位于输出层,输出神经元就是将来自隐藏层的信息输出到外界中,也就是输出最终的结果,如分类结果等。
多层神经网络:拥有多个隐藏层
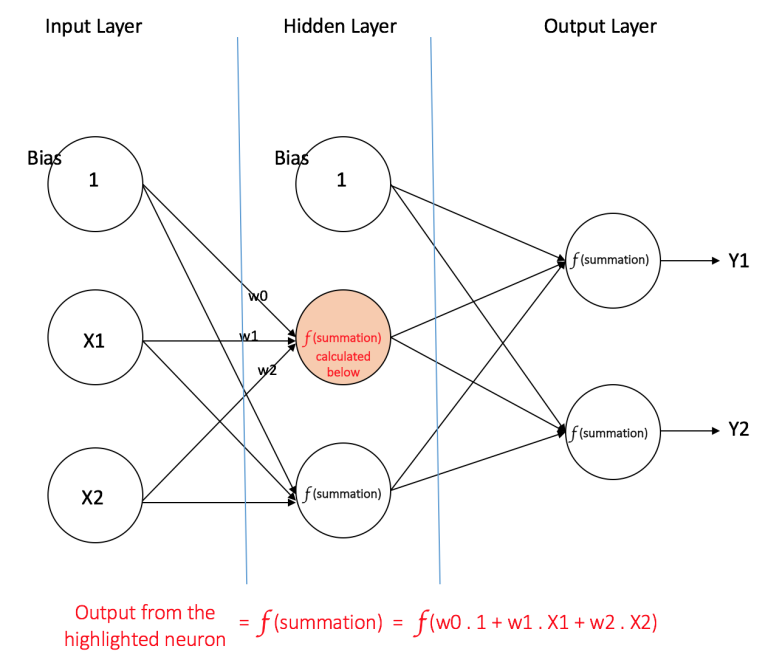
计算损失
当数据传播到输出层后,我们会计算神经网络的输出与真实标签之间的差异(这也是为什么我们需要人工打标的训练数据集)。这个差异叫做损失,损失函数可以是平方误差、交叉熵等等。例如平方差:
L = 0.5*(y - t)^2
反向传播
根据损失来更新神经网络的权重和偏置,以使得损失最小化。这个过程叫做反向传播。在反向传播中,我们首先计算损失关于每个参数的偏导数(梯度),然后将参数沿着梯度的反方向更新,这样可以使得损失下降。这个过程通常使用梯度下降算法或者其变种来进行。
梯度下降:在数学中,梯度是一个向量,指向函数增长最快的方向。相反的方向则是函数下降最快的方向。因此,如果我们有一个需要最小化的目标函数(例如机器学习中的损失函数),我们可以使用梯度下降算法来一步步地移向函数值下降最快的方向,直到找到一个局部最小值(或在凸优化问题中,是全局最小值)。
梯度:∂L/∂w L为误差,w为权重
梯度下降:w := w - η * ∂L/∂w
更新权重参数反复迭代
得到调整后的权重后,我们继续训练达到我们想要的效果,或者达到预设的迭代次数
一个最简单的例子:
一个单层感知器,它只有一个输入节点和一个输出节点。
| 输入 (x) | 权重 (w) | 目标输出 (y) | 预测输出 (y_hat) | 损失 | ∂损失/∂w | 新的权重 (w_new) |
|---|---|---|---|---|---|---|
| 0.5 | 0.6 | 0.8 | 0.3 | 0.25 | -0.5 | 0.65 |
输入 x = 0.5 , 权重 w = 0.6, 真实目标是 0.8,f(x) = wx
网络输出为 y_hat = 0.5 * 0.6 = 0.3
损失函数是均方误差损失函数,即 (y - y_hat)^2。所以我们的损失 L = (0.8 - 0.3)^2 = 0.25。
我们可以计算损失函数关于权重的梯度链式法则展开,即 ∂L/∂w = 2 * (y_hat - y) * x = 2 * (0.3 - 0.8) * 0.5 = -0.5。
∂L/∂w = ∂L/∂y_hat * ∂y_hat/∂w
对于∂L/∂y_hat,因为L = (y - y_hat)^2,所以∂L/∂y_hat = 2*(y_hat - y)。
对于∂y_hat/∂w,因为y_hat = w * x,所以∂y_hat/∂w = x。
学习率(比如 0.1)来更新我们的权重,即 w_new = w - 学习率 * ∂L/∂w = 0.6 - 0.1 * (-0.5) = 0.65。
这个表格中,”损失”是我们计算出的误差值,”∂损失/∂w”是我们计算出的偏导数(也就是损失函数关于权重的梯度),”新的权重 (w_new)”是我们更新后的权重值。通过这样的不断迭代技能逼近于正确的权重 w,使得整个模型的输出更加符合打标数据结果。
Word Embedding 和 Word2vec
回头看一步,计算机能够处理的都是 01 序列这样的二进制流,那么我们怎么让计算机理解语言呢?最简单的就是给文本标号,从而将文本转换成数字,数字就是计算机方便处理操作的形式了。

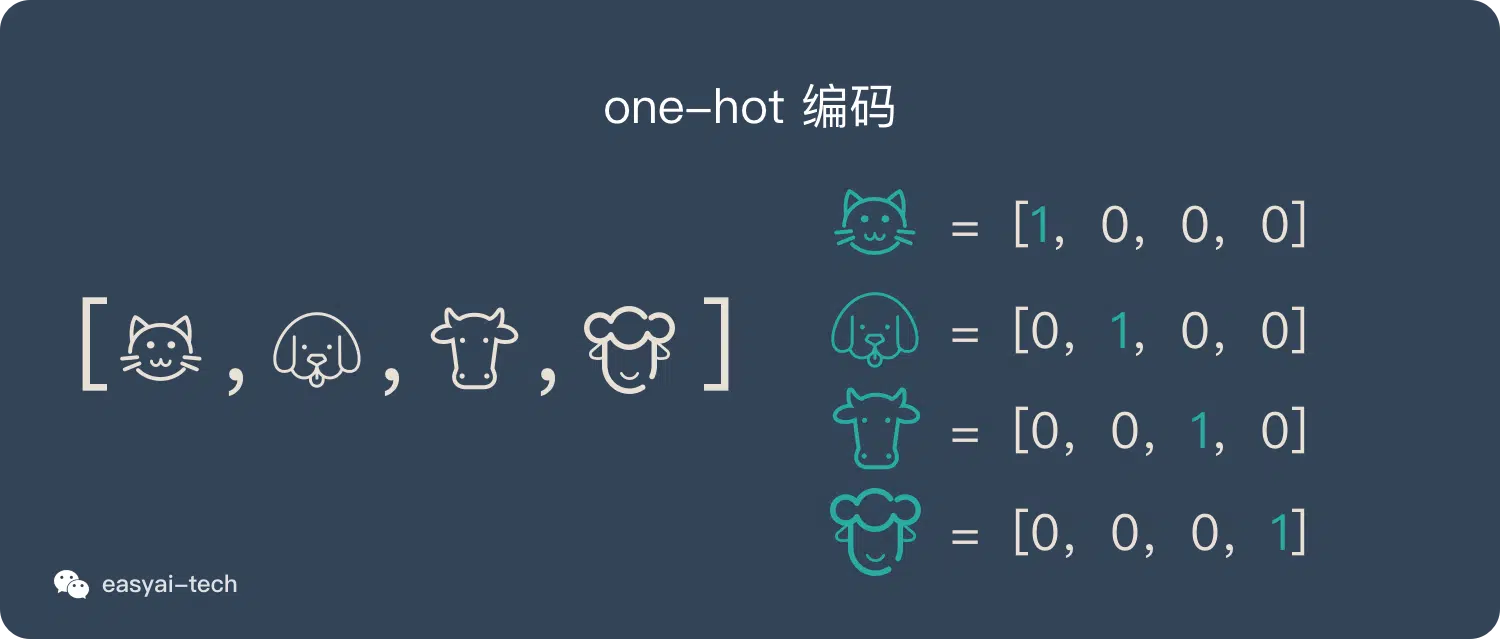
one-hot 编码
最简单的就是将事物与序号进行一一对应,这就是 onehot 编码,在二进制中表示如下图:
word2vec
one-hot 编码有明显的缺陷,比如他没有考虑到两个词之间的含义关联,它们可能相似或者相反,这都没有体现出来;并且每个词都使用一位来表示,会造成维度爆炸的困难。而对于词嵌入:Word Embedding,就会进行考虑两个词之间的关系,并转换为数学意义,词义越近,空间中也越接近,如下图所示:
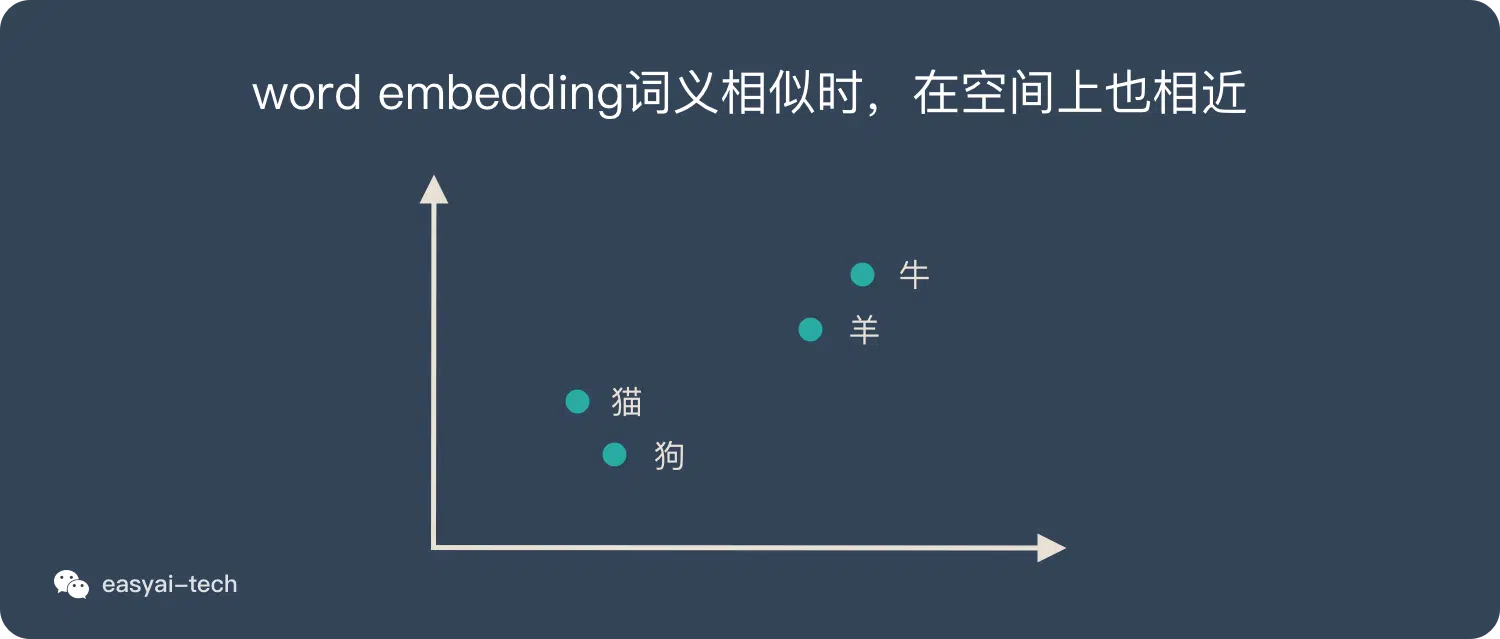
详细 word2vec 的数学原理可见:https://www.cnblogs.com/peghoty/p/3857839.html


词嵌入通过扣掉一个词或者扣掉词附近的词两种方式,利用神经网络来计算出合适的词向量(权重矩阵),从而更高的表达了不同词之间的关系,进行「降低维度」减少复杂度的操作。
但是词嵌入也有一些缺点:
- 词顺序:“我爱你”,“你爱我”,对周围上下文词进行了平等处理,导致两个词向量肯能很相近,但是语义很不同。
- 一词多义:“我喜欢吃苹果”,“我喜欢苹果”,苹果只有一个词向量表示。
CNN
卷积神经网络(CNN)主要运用在视觉处理的方向中,参考了人类视力是如何识别物体的,跟本文的语言模型没有那么关联,这里不做过多的阐述,具体原理可以参考:深入学习卷积神经网络(CNN)的原理知识。这里值得注意的是由于图片的训练集显然是不需要人工打标的,一个正常符合要求的图片就可以给模型训练,所以 CNN 的资料裤是远远多于 NLP 领域的训练资料,这也是后续 NLP 要解决的问题。
RNN
循环神经网络(RNN)主要应用在 NLP 中。例如为了填好下面的空,取前面任何一个词都不合适,我们不但需要知道前面所有的词,还需要知道词之间的顺序。

每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练:
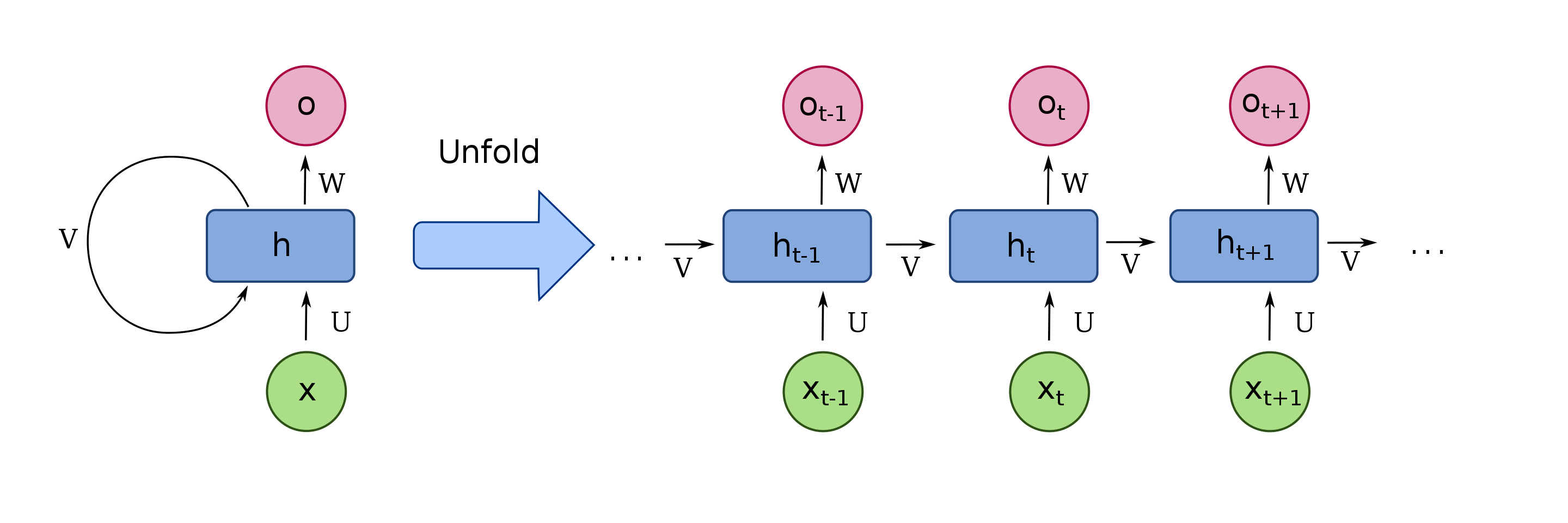
前面的输出都对未来的输出产生影响:
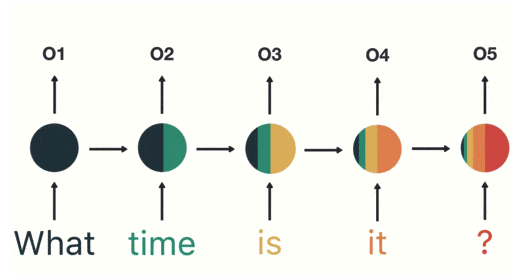
RNN 的缺点:RNN 只能记忆短期的;训练起来慢成本大
针对 RNN 进行改进的 lstm :针对长序列中的重要信息保留,忽略不重要的信息。
Transformer
来到 2017 年最终要的谷歌发布了 Transformer 模型,此后的语言模型基本都基于这一套体系来建立起来,其中最为主要的两个方面就是 Encoder-Decoder 模型,以及自注意力机制,这边我们简单阐述,详细解析见:Transformer 零基础解析教程
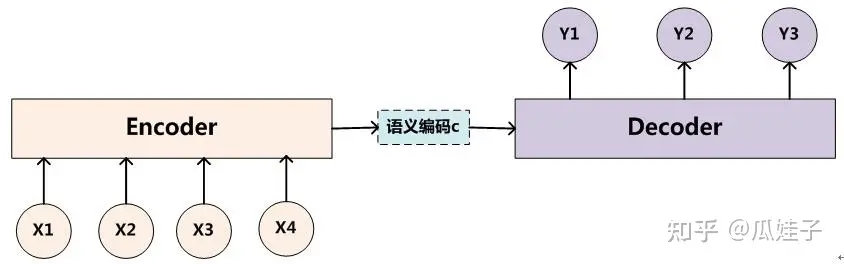
Encoder-Decoder模型
举个具体的例子,我们以翻译给定的输入句子 x 为例,通过Encoder-Decoder框架,最后生成目标句子 Y 。其中 X 和 Y 分别由单词序列构成
原始句子 X=(x1,x2,⋯,xm)
翻译的目标句子 Y=(y1,y2,⋯,yn)
Encoder任务就是对输入句子 X 进行编码,将输入句子通过非线性变换转化为中间语义表示 C :
C=F(x1,x2,⋯,xm)
Decoder任务就是根据句子X 的中间语义表示 C 和之前已经生成的历史信息 y1,y2,⋯,yi−1 来生成 i 时刻要生成的单词 yi 。
yi=G(C,y1,y2,⋯,yi−1)
每个 yi 都依次这么产生,最终看起来就是整个系统根据输入句子 X 生成了目标句子 Y 。
Encoder-Decoder是通用的计算框架,Encoder, Decoder具体用什么模型,都可以自己选择。
自注意力机制
对于一句话,其中的每个词之间都会有一定的关联,例如:I love cats because they are cute
cats 和 they 是有一定的关联的
自注意力机制的工作原理是,它为输入序列中的每一个元素分配一个权重,这个权重取决于该元素与序列中其他元素的关系。这样,模型就可以更好地理解元素之间的依赖关系,从而更好地处理序列数据。
一段自然语言中,其实暗含了:为了得到关于某方面信息 Q,可以通过关注某些信息 K,进而得到某些信息(V)作为结果。
Q 就是 query 检索/查询,K、V 分别是 key、value。所以类似于我们在图书检索系统里搜索「NLP书籍」(这是 Q),得到了一本叫《自然语言处理实战》的电子书,书名就是 key,这本电子书就是 value。只是对于自然语言的理解,我们认为任何一段内容里,都自身暗含了很多潜在 Q-K-V 的关联。这是整体受到信息检索领域里 query-key-value 的启发的。
计算Query、Key和Value:首先,我们将输入的词向量(设为X)分别与三个权重矩阵W_q(Query权重矩阵)、W_k(Key权重矩阵)、W_v(Value权重矩阵)相乘,得到Query、Key和Value。计算公式如下:
Query = X * W_q
Key = X * W_k
Value = X * W_v计算注意力权重:接着,我们计算每个词的Query与所有词的Key的点积,然后通过softmax函数将点积的结果转换为概率分布,这个概率分布就是我们所说的注意力权重,反映了当前词与其他词在语义上的关联程度。计算公式如下:
注意力权重 = softmax(Query * Key的转置)
计算输出:最后,我们将注意力权重与Value做加权求和,得到最后的输出。计算公式如下:
输出 = 注意力权重 * Value
新的词向量根据损失函数和梯度下降等方法来进行更新 W_q, W_k, W_v 向量
最终得到了一组最终的词向量,他们之间的关系更加符合他们之间语义的关联
Transformer模型:
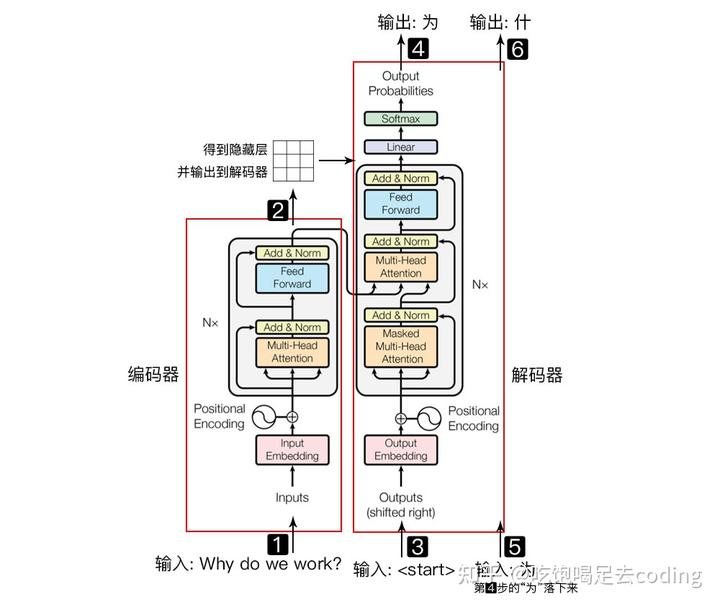
位置向量
因为是没有像 rnn 那样的时间序列一样,而是可以并发的训练得到词向量,所以自注意力计算时没有考虑位置的因素,所以在词嵌入向量中添加位置向量,然后再代入训练中,就能保留位置信息。
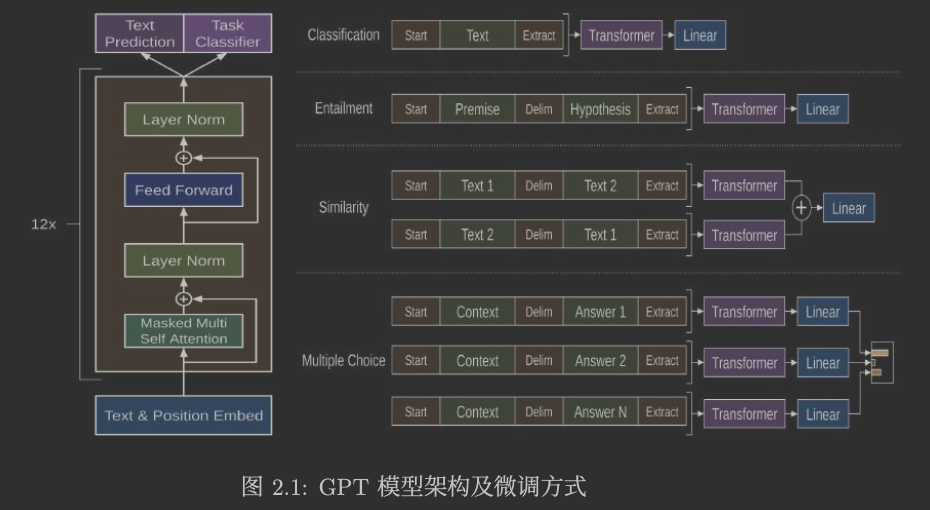
GPT-1
因为标注数据的代价巨大,NLP 中没有 CV 中那么多好的训练样本,所以在 GPT-1 中只使用 Decoder 来做自监督学习,基于自注意力机制,来进行预训练,从而学习到更深层次的语法和语义信息。比如给出一篇文章,他本身是没有打标的但是有一个天然的词语顺序,通过自注意力等处理,可以来获得每个词的合理词向量,其中包含了一定的语义。
之后GPT-1 接着使用了有标注的数据进行有监督的微调使得模型能够更好地适应下游任务。这样能够做到更高的通用迁移。GPT-1 的目标是学习到一个通用的自然语言表征,并在之后 通过简单调节适应很大范围上的任务。
Bert
和 GPT 不同的是 Bert 只使用了 Transformer 的编码器。Transformer 的编码器就像完形填空,在预测每个词时,是知道前后(过去和未来)的文本内容的;但是 Transformer 的解码器仅知道前面的文本(过去)来预测词,相当于在预测未来。
对于 GPT:
1 | I -> I accessed |
对于 Bert,进行类似完形填空
1 | I accessed the [MASK] account -> [MASK]=bank |
GPT-2
更大的数据集,以及一些优化,证明了其没有微调的情况下通过无监督学习也可以效果很好
GPT-3
更大的模型参数,更大的数据集,暂时无法解释为什么这么效果这么好
Prompt(In-Context Learning) 和 思维链(Chain-of-Thought)
大模型的两个突出特征:ICL 和 CoT
一个预训练模型,在处理下游任务时,不微调模型参数,只需要在输入时加一些示例,就能有 SOTA 的表现,这就是模型的上下文学习(In-Context Learning,ICL)能力:
| x | 本周末周边自驾两天一夜,最推荐的地方? |
|---|---|
| f(x) | 我的所在地是<杭州>,请对下面这个问题给出 5 个不同的答案并且每个答案都带一条简短的理由:本周末周边自驾两天一夜,最推荐的地方? |
| y | 南浔古镇,有保存完好的明清时期建筑;莫干山,远离城市喧嚣亲近大自然享受慢节奏的民宿生活;千岛湖,一边吃美味鱼宴一边赏着湖光山色水清鱼跃绝美的自然风光;乌镇,江南水乡特色韵味古镇建筑有着深厚的文化积淀;普陀山,佛教圣地有着浓厚的宗教氛围素有“海上名山”之称。 |
| g(y) | 1、对 y 中几条结果,查询天气、最新交通管制措施、游客接待政策等等(假设因此剔除了南浔古镇、千岛湖);2、剔除用户已去过的目的地(假设用户已授权模型访问其旅游平台账户,剔除了普陀山);3、对 y 的结果进行优化并保留推荐值最高的结果「莫干山 ……」并输出:莫干山,<推荐亮点>,<天气>,<交通情况>,<推荐美食>,<推荐酒店/民宿>,<推荐自驾路线>。 |
f(x) 就是 Prompt Engineering

思维链:Let’s think step by step
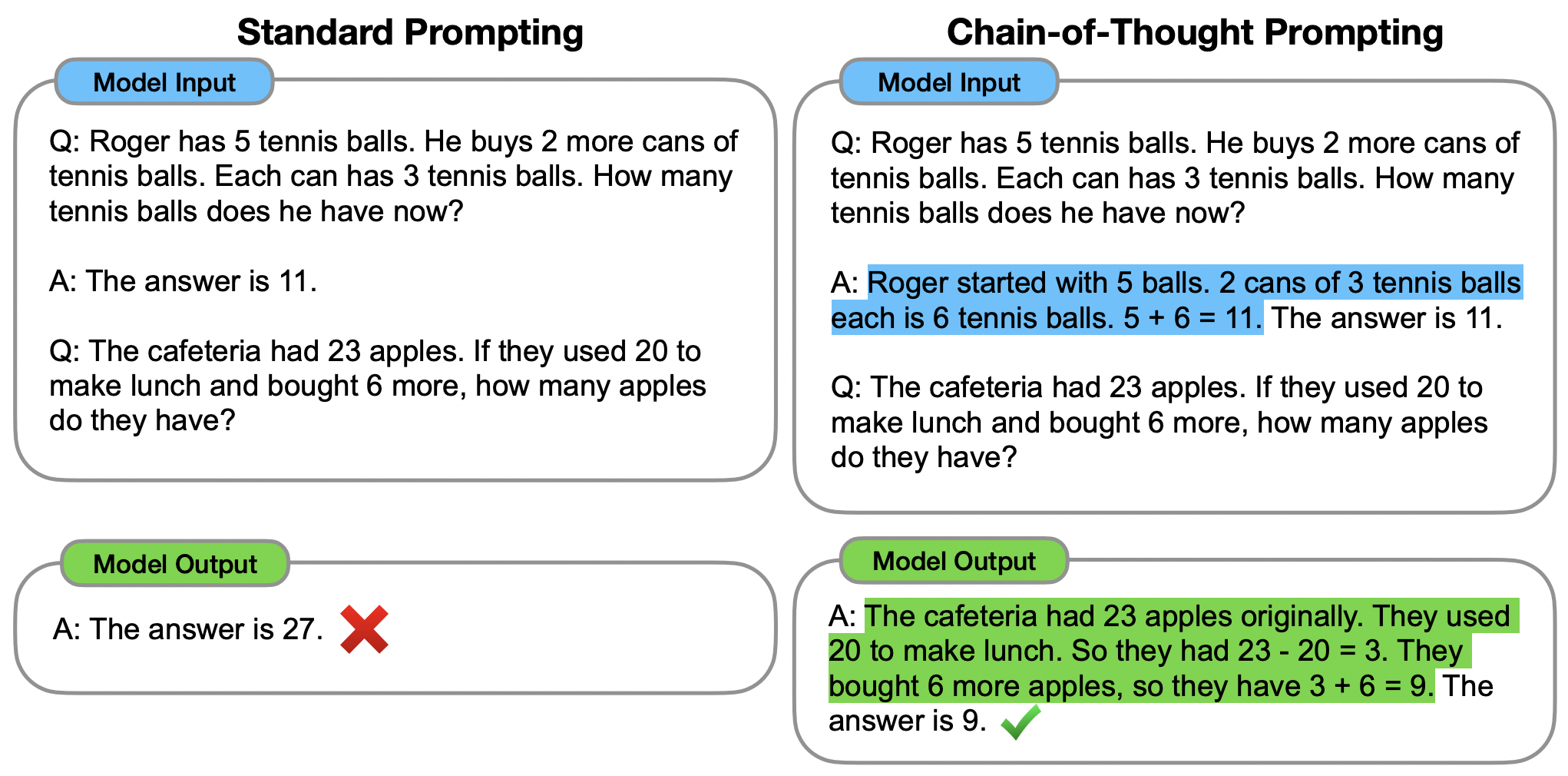
InstructGPT
人工反馈的强化学习(Reinforcement Learning with Human Feedback)
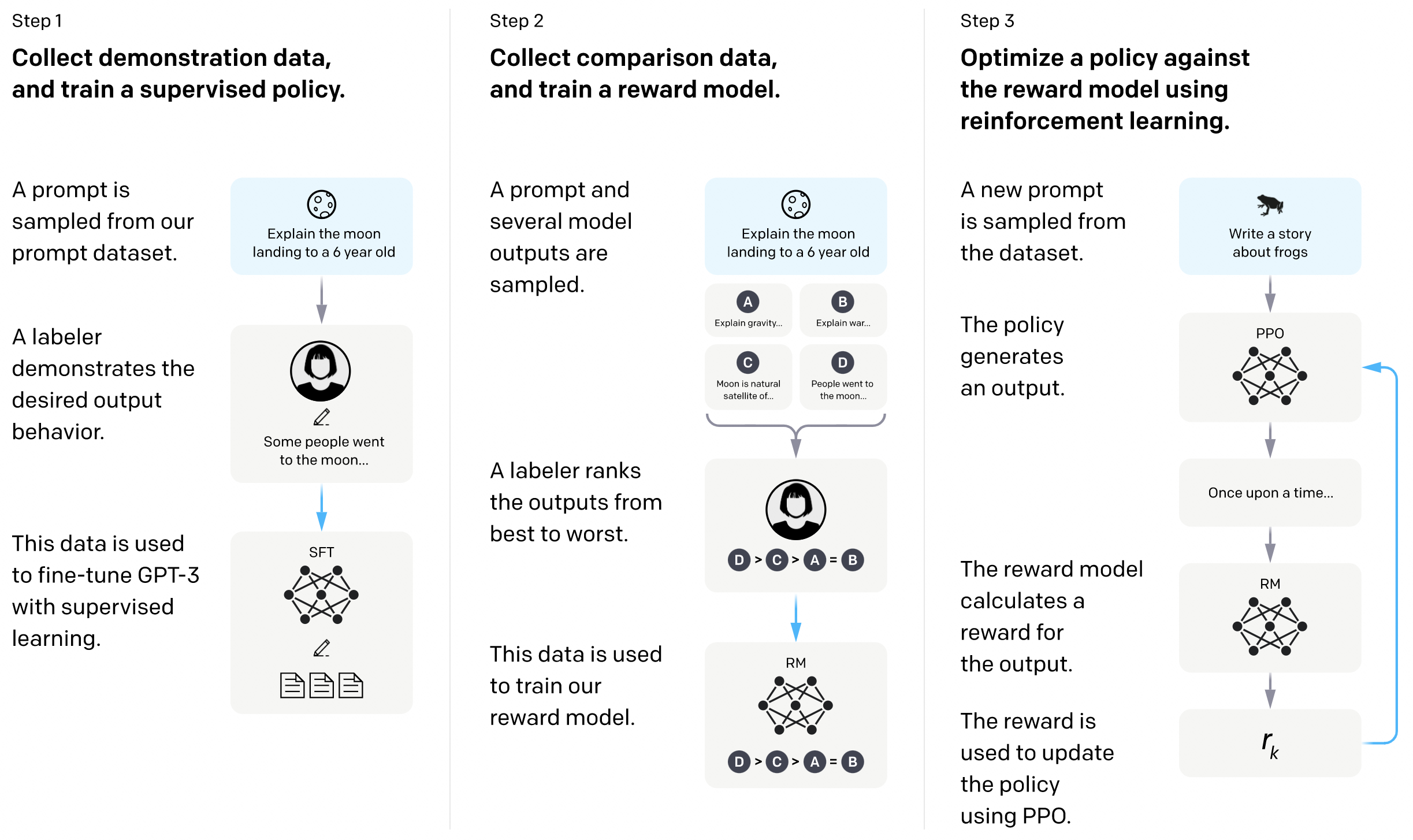
- 第一步监督学习微调出一个模型A
- 第二步训练一个奖励模型B
- 第三步用奖励模型B通过强化学习训练第一步的模型A
ChatGPT
和 InstructionGPT 训练数据和方法有有些区别,并且是对话式的
PLam2
谷歌的 LLM 也是基于 Transformer ,翻了论文基本没什么具体内容,主要强调的是训练数据不一样,更加基于人类价值观,更少的参数带来更高的性能 , Sec-PLam ,样本用安全相关的东西来训练的
- VirusTotal Code Insight 用 Sec-Plam 来解释哪些脚本存在威胁
- Mandiant Breach Analytics for Chronicle利用 Google Cloud 和 Mandiant Threat Intelligence 自动提醒您环境中的活动漏洞。
总结思考
到这里为止,我们可以看到语言模型在最近几年的主要发展,在谷歌公开的 Transformer 模型基础上,OpenAI 进行不断的优化,更大的模型规模与参数,更优质与庞大的训练资料,让 LLM 从量变产生了质变,涌现出的能力为后来人指明了大语言模型方向的可能性。
但是我们也可以看到机器学习,深度学习越来越向工程化发展,很多时候并没有一个完备的数学理论作为基础,很多算法工程师进行模型设计时甚至无法说明为什么,很多通过实验来进行说明,模型的可解释性发展并没有跟上模型能力的发展,这在笔者看来也是一种遗憾,希望能够在未来我们能够不仅仅让模型「理解」我们,同时我们也能够「理解」模型。
最后,笔者坚信 AI 一定是未来提高生产力的必经之路,让我们期盼这科幻的未来吧!