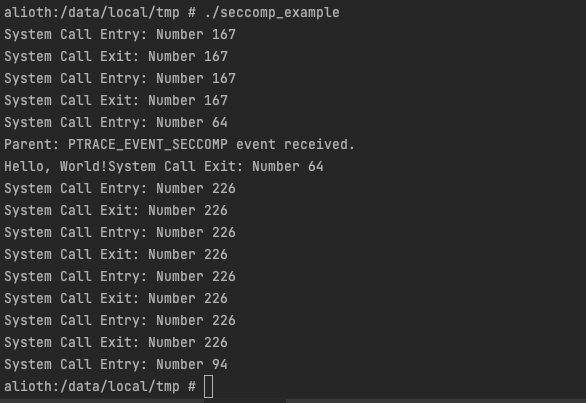
seccomp(全称secure computing mode)是 linux kernel支持的一种安全机制。在 linux 系统里,大量的系统调用直接暴露给用户态程序。但是并不是所有的系统调用都被需要,而且不安全的代码滥用系统调用会对系统造成安全威胁。通过 seccomp,我们限制程序使用某些系统调用,这样可以减少系统的暴露面,同时是程序进入一种“安全”的状态,这也就是沙箱的雏形。
# cat /proc/version Linux version 4.19.157-perf-gf8cdf943b2b3 (builder@pangu-build-component-vendor-96687-7t4pv-tshlp-g02mt) (clang version 10.0.7 for Android NDK, GNU ld (binutils-2.27-bd24d23f) 2.27.0.20170315) #1 SMP PREEMPT Wed Jun 7 08:25:17 UTC 2023
/* Specify the type of the final component during the * initialization of a binding. This variable is first * defined in bind_path() then used in build_glue(). */ mode_t glue_type;
/********************************************************************** * Shared or private resources, depending on the CLONE_FS/VM flags. * **********************************************************************/
/* 与文件系统名称空间相关的信息。 */ FileSystemNameSpace *fs;
/* 虚拟堆,使用常规内存映射进行模拟。 */ Heap *heap;
/********************************************************************** * Shared resources until the tracee makes a call to execve(). * **********************************************************************/
/* 执行程序的路径 */ char *exe; char *new_exe;
/********************************************************************** * Shared or private resources, depending on the (re-)configuration * **********************************************************************/
case0: /* child */ /* Declare myself as ptraceable before executing the * requested program. */ status = ptrace(PTRACE_TRACEME, 0, NULL, NULL); if (status < 0) { note(tracee, ERROR, SYSTEM, "ptrace(TRACEME)"); return -errno; }
/* Synchronize with the tracer's event loop. Without * this trick the tracer only sees the "return" from * the next execve(2) so PRoot wouldn't handle the * interpreter/runner. I also verified that strace * does the same thing. */ kill(getpid(), SIGSTOP);
/* Improve performance by using seccomp mode 2, unless * this support is explicitly disabled. */ if (getenv("PROOT_NO_SECCOMP") == NULL) (void) enable_syscall_filtering(tracee);
/* Now process is ptraced, so the current rootfs is already the * guest rootfs. Note: Valgrind can't handle execve(2) on * "foreign" binaries (ENOEXEC) but can handle execvp(3) on such * binaries. */ execvp(tracee->exe, argv[0] != NULL ? argv : default_argv); return -errno;
default: /* parent */ /* We know the pid of the first tracee now. */ tracee->pid = pid; return0; }
/* Add the sysnums required by PRoot to the list of filtered * sysnums. TODO: only if path translation is required. */ status = merge_filtered_sysnums(tracee->ctx, &filtered_sysnums, proot_sysnums); if (status < 0) return status;
/* Merge the sysnums required by the extensions to the list * of filtered sysnums. */ if (tracee->extensions != NULL) { LIST_FOREACH(extension, tracee->extensions, link) { if (extension->filtered_sysnums == NULL) continue;
status = merge_filtered_sysnums(tracee->ctx, &filtered_sysnums, extension->filtered_sysnums); if (status < 0) return status; } }
status = set_seccomp_filters(filtered_sysnums); if (status < 0) return status;
elseif (WIFSTOPPED(tracee_status)) { /* Don't use WSTOPSIG() to extract the signal * since it clears the PTRACE_EVENT_* bits. */ signal = (tracee_status & 0xfff00) >> 8;
/* Distinguish some events from others and * automatically trace each new process with * the same options. * * Note that only the first bare SIGTRAP is * related to the tracing loop, others SIGTRAP * carry tracing information because of * TRACE*FORK/CLONE/EXEC. */ if (deliver_sigtrap) break; /* Deliver this signal as-is. */
deliver_sigtrap = true;
/* Try to enable seccomp mode 2... */ status = ptrace(PTRACE_SETOPTIONS, tracee->pid, NULL, default_ptrace_options | PTRACE_O_TRACESECCOMP); if (status < 0) { /* ... otherwise use default options only. */ status = ptrace(PTRACE_SETOPTIONS, tracee->pid, NULL, default_ptrace_options); if (status < 0) { note(tracee, ERROR, SYSTEM, "ptrace(PTRACE_SETOPTIONS)"); exit(EXIT_FAILURE); } } }
/* Fall through. */ case SIGTRAP | 0x80: signal = 0;
/* This tracee got signaled then freed during the sysenter stage but the kernel reports the sysexit stage; just discard this spurious tracee/event. */ if (tracee->exe == NULL) { tracee->restart_how = PTRACE_CONT; /* SYSCALL OR CONT */ return0; }
switch (tracee->seccomp) { case ENABLED: if (IS_IN_SYSENTER(tracee)) { /* sysenter: ensure the sysexit * stage will be hit under seccomp. */ tracee->restart_how = PTRACE_SYSCALL; tracee->sysexit_pending = true; } else { /* sysexit: the next sysenter * will be notified by seccomp. */ tracee->restart_how = PTRACE_CONT; tracee->sysexit_pending = false; } /* Fall through. */ case DISABLED: translate_syscall(tracee);
/* This syscall has disabled seccomp. */ if (tracee->seccomp == DISABLING) { tracee->restart_how = PTRACE_SYSCALL; tracee->seccomp = DISABLED; }
break;
case DISABLING: /* Seccomp was disabled by the * previous syscall, but its sysenter * stage was already handled. */ tracee->seccomp = DISABLED; if (IS_IN_SYSENTER(tracee)) tracee->status = 1; break; } break;
case SIGTRAP | PTRACE_EVENT_SECCOMP2 << 8: case SIGTRAP | PTRACE_EVENT_SECCOMP << 8: { unsignedlong flags = 0;
/* Use the common ptrace flow if seccomp was * explicitely disabled for this tracee. */ if (tracee->seccomp != ENABLED) break;
status = ptrace(PTRACE_GETEVENTMSG, tracee->pid, NULL, &flags); if (status < 0) break;
/* Use the common ptrace flow when * sysexit has to be handled. */ if ((flags & FILTER_SYSEXIT) != 0) { tracee->restart_how = PTRACE_SYSCALL; break; }
/* Otherwise, handle the sysenter * stage right now. */ tracee->restart_how = PTRACE_CONT; translate_syscall(tracee);
/* This syscall has disabled seccomp, so move * the ptrace flow back to the common path to * ensure its sysexit will be handled. */ if (tracee->seccomp == DISABLING) tracee->restart_how = PTRACE_SYSCALL; break; }
第一个 case SIGTRAP: 是用来在首次收到信号时设置 PTRACE_O_TRACESECCOMP 的,在真要触发 BRF 的逻辑时,触发的顺序是:
switch (tracee->seccomp) { case ENABLED: if (IS_IN_SYSENTER(tracee)) { /* sysenter: ensure the sysexit * stage will be hit under seccomp. */ tracee->restart_how = PTRACE_SYSCALL; tracee->sysexit_pending = true; } else { /* sysexit: the next sysenter * will be notified by seccomp. */ tracee->restart_how = PTRACE_CONT; tracee->sysexit_pending = false; } /* Fall through. */ case DISABLED: translate_syscall(tracee);
/* This syscall has disabled seccomp. */ if (tracee->seccomp == DISABLING) { tracee->restart_how = PTRACE_SYSCALL; tracee->seccomp = DISABLED; }
break;
case DISABLING: /* Seccomp was disabled by the * previous syscall, but its sysenter * stage was already handled. */ tracee->seccomp = DISABLED; if (IS_IN_SYSENTER(tracee)) tracee->status = 1; break; } break;
/* Distinguish some events from others and * automatically trace each new process with * the same options. * * Note that only the first bare SIGTRAP is * related to the tracing loop, others SIGTRAP * carry tracing information because of * TRACE*FORK/CLONE/EXEC. */ if (deliver_sigtrap) break; /* Deliver this signal as-is. */
deliver_sigtrap = true;
/* Try to enable seccomp mode 2... */ status = ptrace(PTRACE_SETOPTIONS, tracee->pid, NULL, default_ptrace_options | PTRACE_O_TRACESECCOMP); if (status < 0) { seccomp_enabled = false; /* ... otherwise use default options only. */ status = ptrace(PTRACE_SETOPTIONS, tracee->pid, NULL, default_ptrace_options); if (status < 0) { note(tracee, ERROR, SYSTEM, "ptrace(PTRACE_SETOPTIONS)"); exit(EXIT_FAILURE); } } else { if (getenv("PROOT_NO_SECCOMP") == NULL) seccomp_enabled = true; } } /* Fall through. */ case SIGTRAP | PTRACE_EVENT_SECCOMP2 << 8: case SIGTRAP | PTRACE_EVENT_SECCOMP << 8:
if (tracee->seccomp == DISABLING) tracee->restart_how = PTRACE_SYSCALL; break; } }
/* Fall through. */ case SIGTRAP | 0x80:
signal = 0;
/* This tracee got signaled then freed during the sysenter stage but the kernel reports the sysexit stage; just discard this spurious tracee/event. */
if (tracee->exe == NULL) { tracee->restart_how = PTRACE_CONT; /* SYSCALL OR CONT */ return0; }
switch (tracee->seccomp) { case ENABLED: if (IS_IN_SYSENTER(tracee)) { /* sysenter: ensure the sysexit * stage will be hit under seccomp. */ tracee->restart_how = PTRACE_SYSCALL; tracee->sysexit_pending = true; } else { /* sysexit: the next sysenter * will be notified by seccomp. */ tracee->restart_how = PTRACE_CONT; tracee->sysexit_pending = false; } /* Fall through. */ case DISABLED: translate_syscall(tracee);
/* This syscall has disabled seccomp. */ if (tracee->seccomp == DISABLING) { tracee->restart_how = PTRACE_SYSCALL; tracee->seccomp = DISABLED; }
break;
case DISABLING: /* Seccomp was disabled by the * previous syscall, but its sysenter * stage was already handled. */ tracee->seccomp = DISABLED; if (IS_IN_SYSENTER(tracee)) tracee->status = 1; break; } break;
如果需要 FILTER_SYSEXIT 那么 Fall through 到 case SIGTRAP | 0x80: 执行
1 2 3 4 5 6 7
case ENABLED: if (IS_IN_SYSENTER(tracee)) { /* sysenter: ensure the sysexit * stage will be hit under seccomp. */ tracee->restart_how = PTRACE_SYSCALL; tracee->sysexit_pending = true; }
继续 Fall Through 到,调用 translate_syscall 对函数调用前的参数进行处理。
1 2 3 4 5 6 7 8 9 10
case DISABLED: translate_syscall(tracee);
/* This syscall has disabled seccomp. */ if (tracee->seccomp == DISABLING) { tracee->restart_how = PTRACE_SYSCALL; tracee->seccomp = DISABLED; }
break;
重启后因为 PTRACE_SYSCALL 再次触发 case SIGTRAP | 0x80: 同理到
1 2 3 4 5 6
else { /* sysexit: the next sysenter * will be notified by seccomp. */ tracee->restart_how = PTRACE_CONT; tracee->sysexit_pending = false; }